Работа с HTTP в Python неоправданно громоздка. Входящий в комплект urllib2 модуль является исчерпывающим за счет большой сложности. Модуль requests от Kenneth Reitz, напротив, намеренно избегает завершенности в пользу упрощения общих случаев использования.
Простой пример
Представьте, что мы пытаемся получить ресурс по адресу: //example.test/ и посмотреть код состояния, его заголовок content-type, а также содержание состояния. Это довольно просто как и с urllib2, так и с Requests:
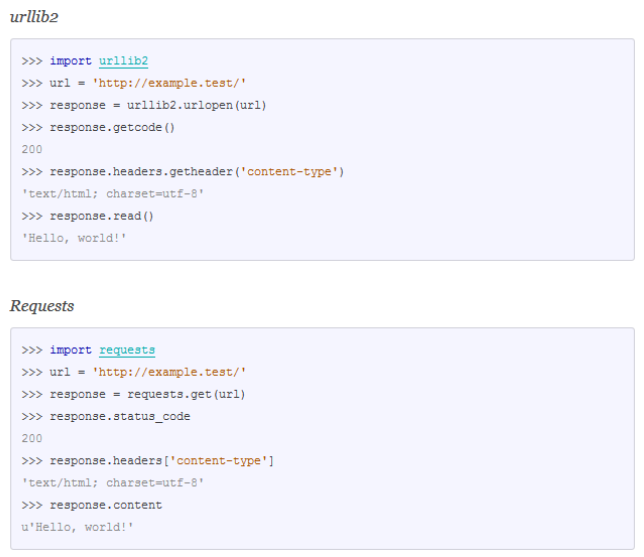
Несмотря на то, что requests и urllib2 очень похожи, между ними существует значительная разница.
- в requests oтветы автоматически декодируется в Unicode
- oтветы автоматически сохраняют содержание, так что вы можете получить доступ к ним многократно, в отличие одноразово-читаемых файл-подобных объектов, возвращаемых urllib2.urlopen().
Вторая проблема особенно раздражает, когда печатаем код в Python REPL.
Более сложный пример
Давайте теперь попробуем что-нибудь посложнее, а именно получить ресурс по адресу http://foo.test/secret, который требует базовую проверку подлинности HTTP. Используя предыдущий в качестве шаблона, казалось бы, нам просто нужно заменить команду на urllib2.urlopen() или requests.get () чем-то, что отсылает имя пользователя и пароль вместе с запросом.
Вот тут-то urllib2 нас подводит.
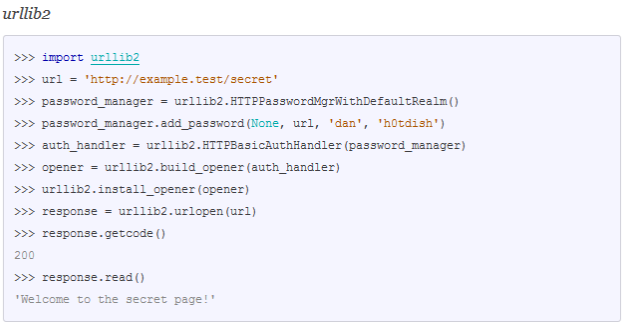
Выглядит довольно сложно по сравнению с requests, где мы просто добавляем ключевой параметр auth:
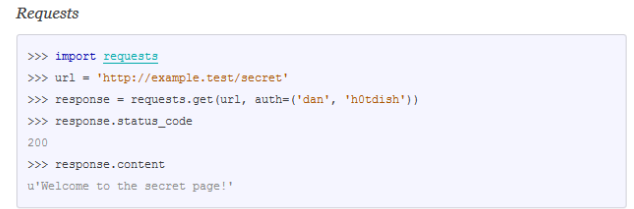
Ошибки
С requests также намного удобнее обрабатывать ошибки. Если в проведенном примере выше был использован неверный логин и пароль, urllib2 выдаст urllib2.URLError, а requests вернет нормальный объект ответа, как и ожидалось. Единственное, что требуется для определения, был ли успешным запрос – это булевый атрибут response.ok:

Другие особенности
- Requests выдает п простой API для HEAD, POST, PUT, PATCH и DELETE.
- Он обрабатывает многокомпонентные загрузки файлов, а также автоматические кодирующие словари.
- Подробная документация
- И многое другое …..
Обратите внимание requests, когда нужно будет получить данные по протоколу HTTP!